


clickhouse聚合之探索聚合内部机制
大家好,我是奇想派,可以叫我奇奇。
将数据进行聚合是分析数据库的一项关键功能。我们无法从数十亿次的访问量列表数据列表中得出太多结论。但是,我们可以很容易地理解,本月的平均访问量从上个月日活100到这个有日活1000。在ClickHouse中,我们将此类汇总称为聚合**,这是从大型数据集中掌握意义的基本方法。**
在本博客系列中,我们将探讨聚合在 ClickHouse 中的工作原理、如何衡量其性能以及如何使其更快、更高效。为了便于阅读,我们将使用简单的示例,但它们显示的原则适用于更复杂的查询。
实验前提:
- ClickHouse 版本: 22.1.3.7
- 操作系统:centos7.8
** 我们将使用随机生成的飞机起航的数据集,来演示 ClickHouse 如何在内部处理聚合。下面是一个查询,用于查找航空公司的平均起飞延误。它按降序对结果进行排序,并返回平均延迟时间最长的三家航空公司:**
聚合查询内部是如何工作的?
让我们使用一个简单的示例来演示 ClickHouse 如何在内部处理聚合。下面是一个查询,用于查找美国航空公司的平均起飞延误。它按降序对结果进行排序,并返回平均延迟时间最长的三家航空公司:
SELECT Carrier, avg(DepDelay) AS Delay
FROM ontime
GROUP BY Carrier
ORDER BY Delay DESC LIMIT 3
. . .
┌─Carrier─┬──────────────Delay─┐
│ B6 │ 12.058290698785067 │
│ EV │ 12.035012037703922 │
│ NK │ 10.437692933474269 │
└─────────┴────────────────────┘
在我的单个云主机上,此查询将在大约 0.75 秒后返回。它读取完整的数据集,即197M行来获得这个答案,这非常快。那么,ClickHouse内部发生了什么?下图说明了查询处理流。
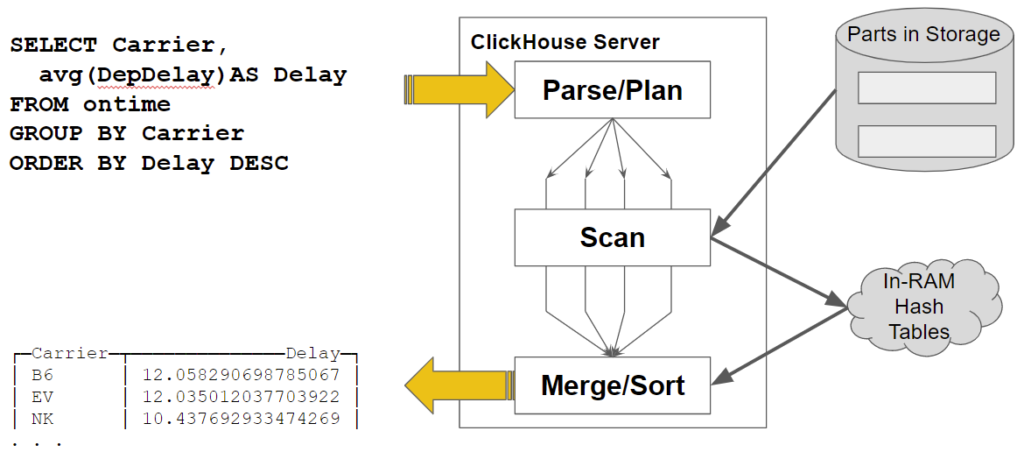
让我们重点介绍处理扫描数据时发生的聚合的两个重要特征。
- 查询处理是并行化的**。ClickHouse 分配了多个线程(在本例中为四个线程),这些线程独立读取其中的不同表部分和数据块。它们读取数据并动态执行初始聚合。**
- ****聚合在哈希表中累积。****每个 GROUP BY 值都有一个键。
扫描结束后,最后一步是合并所有聚合并对其进行排序。这就引出了下一个问题。ClickHouse 计算如何并行聚合?下图显示其工作原理。
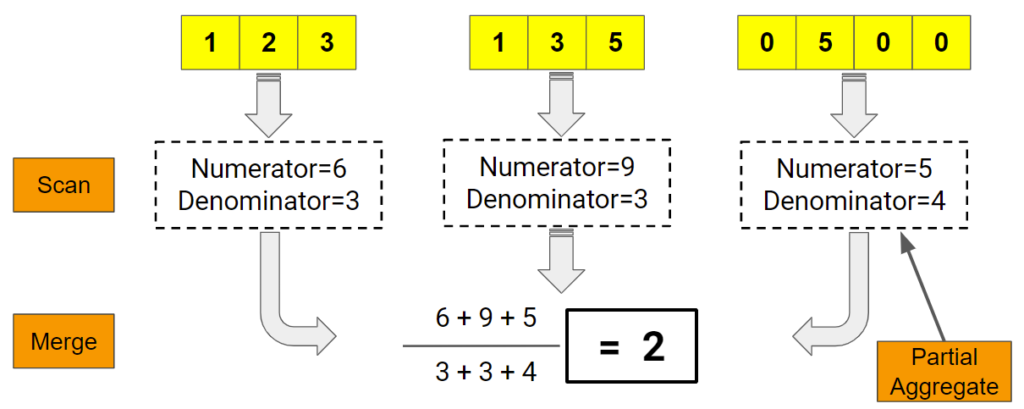
这就引出了最后一个问题。ClickHouse 如何在合并之前收集和存储部分聚合?正如我们刚刚提到的,答案是哈希表,其中键对应于值,部分聚合存储为与每个键关联的列表。如下图。
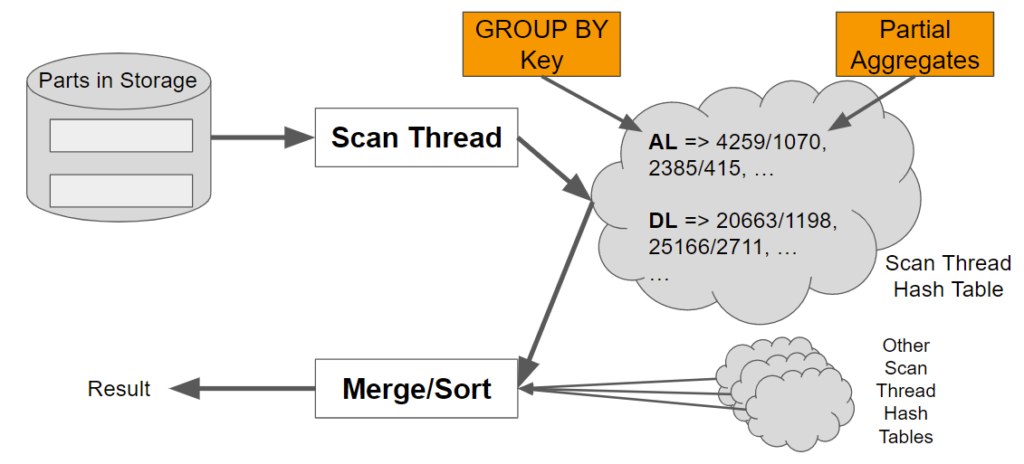
ClickHouse聚合实际上比上图所示的更复杂(也更快)。
首先,ClickHouse根据密钥的数量和类型选择不同的聚合方法以及不同的哈希表配置,数据结构和收集方法因数据而异。此专用化可确保聚合方法考虑不同数据类型中的性能差异。GROUP BY
其次,ClickHouse聚合是动态的**。ClickHouse从单级哈希表开始,对于少量密钥,这些哈希表的速度更快。随着存储密钥数量的增加,ClickHouse可以自动切换到运行速度更快的两级哈希表。ClickHouse实际上适应了实际数据。它非常快,没有大量的查询规划开销。**
顺便说一句,将聚合排列到按键组织的队列中,然后合并队列内容可能听起来很熟悉。你可能听说过MapReduce。这是Jeff Dean和Sanjay Ghemawat的一篇著名论文的主题,为Hadoop的发展做出了贡献。数据仓库实际上在Hadoop广泛普及之前使用这种技术已经很多年了。
使用衡量聚合性能的工具
现在我们已经研究了聚合的工作原理,很明显,有一些与聚合相关的有趣问题。我们需要工具来了解查询速度、使用的内存和其他特征。我们还需要一种方法来窥视查询处理的掩护,以仔细查看聚合详细信息。
使用system.query_log
好消息是,system.query_log表恰好包含评估聚合性能所需的信息。默认情况下,当您安装ClickHouse时,它将处于启用状态。下面是一个简单的查询,用于找出示例 SQL 所需的时间和内存,该示例在列表中显示为第三位。
SELECT
event_time, query_duration_ms / 1000 AS secs,
formatReadableSize(memory_usage) AS memory,
Settings['max_threads'] AS threads,
substring(query, 1, 20) AS query
FROM system.query_log AS ql
WHERE (user = 'default') AND (type = 'QueryFinish')
ORDER BY event_time DESC
LIMIT 50
Query id: 94c00711-31cb-4280-8270-717ccf942748
┌──────────event_time─┬──secs─┬─memory───┬─threads─┬─query────────────────┐
│ 2022-03-14 13:30:03 │ 0.007 │ 0.00 B │ 4 │ select event_time, q │
│ 2022-03-14 13:23:52 │ 0.032 │ 0.00 B │ 4 │ select event_time, q │
│ 2022-03-14 13:23:40 │ 2.023 │ 0.00 B │ 4 │ SELECT Carrier, avg( │
│ 2022-03-14 13:23:20 │ 0.002 │ 0.00 B │ 4 │ SELECT message FROM │
│ 2022-03-14 13:23:20 │ 0.061 │ 4.24 MiB │ 4 │ SELECT DISTINCT arra │
. . .
system.query_log表非常通用,但我们将重点介绍几个关键列。首先,每个查询记录多个事件。事件名称位于类型****列中。我们将重点介绍 QueryFinish 事件类型,因为它显示了查询的完整统计信息。
其次,query_duration_ms列和memory_usage列分别显示查询的持续时间和内存使用情况。它们很容易解释,但您可能会惊讶地发现许多查询似乎使用0字节的RAM。这显然是不可能的。
正在发生的事情很简单。ClickHouse 会忽略低于 max_untracked_memory 值(默认值为 4,194,304)的线程内存值。我们可以通过将值设置为低值(如 1 字节)来找出用于查询的内存。下面是一个示例。
SET max_untracked_memory = 1
SELECT Carrier, avg(DepDelay) AS Delay
FROM ontime
GROUP BY Carrier
ORDER BY Delay DESC LIMIT 3
SELECT
event_time, query_duration_ms / 1000 AS secs,
formatReadableSize(memory_usage) AS memory,
Settings['max_threads'] AS threads,
substring(query, 1, 20) AS query
FROM system.query_log
WHERE (user = 'default') AND (type = 'QueryFinish')
ORDER BY event_time DESC
LIMIT 50
┌──────────event_time─┬──secs─┬─memory───┬─threads─┬─query────────────────┐
│ 2022-03-14 13:35:09 │ 0.85 │ 8.40 MiB │ 4 │ SELECT Carrier, avg( │
. . .
平均值使用的内存相对较少,因为聚合很简单。更复杂的聚合使用更多的内存,因此在这些情况下,您无需调整max_untracked_memory即可了解正在使用的内存。
system.query_log中还有许多其他有用的列。但是,上面显示的简单查询已经提供了丰富的信息,使我们能够衡量聚合处理中的权衡。在闲暇时检查其他人。
为查询启用消息日志
另一个重要的工具是ClickHouse服务器消息日志。您可以直接查看消息日志,将它们定向到system.text_log表,或者使用 send_message_logs 属性在 clickhouse-client 中启用它们。下面介绍如何启用跟踪消息以显示查询处理的血腥详细信息,以及几条诱人的消息以显示您可以学习的内容。
SET send_logs_level = 'trace'
SELECT Carrier, FlightDate, avg(DepDelay) AS Delay
FROM ontime
GROUP BY Carrier, FlightDate
ORDER BY Delay DESC LIMIT 3
[chi-clickhouse101-clickhouse101-0-0-0] 2022.03.16 22:23:39.802817 [ 485 ] {287891a8-d444-4d43-a96a-ca7aa5cd6ff5} <Debug> executeQuery: (from xx.xxx.xx.xx:43802, user: default) -- #2
SELECT Carrier, FlightDate, avg(DepDelay) AS Delay FROM ontime GROUP BY Carrier, FlightDate ORDER BY Delay DESC LIMIT 3 ;
. . .
[chi-clickhouse101-clickhouse101-0-0-0] 2022.03.16 22:23:39.810727 [ 282 ] {287891a8-d444-4d43-a96a-ca7aa5cd6ff5} <Trace> Aggregator: Aggregation method: keys32
. . .
[chi-clickhouse101-clickhouse101-0-0-0] 2022.03.16 22:23:40.530650 [ 282 ] {287891a8-d444-4d43-a96a-ca7aa5cd6ff5} <Debug> AggregatingTransform: Aggregated. 50160884 to 42533 rows (from 382.70 MiB) in 0.721708392 sec. (69502980.090 rows/sec., 530.28 MiB/sec.)
调试级别输出足以查看线程上的计时。如果你想看到像选择的聚合方法这样的东西(例如,如上所示的keys32****),trace就是你的朋友。它为大型查询生成了惊人的输出量。
结论
在本文章中,我们查看了 ClickHouse 聚合内部结构,也了解了聚合的工作原理。后面还介绍了跟踪聚合行为的两个基本工具:system.query_log表和 ClickHouse 调试和跟踪日志。
在下一篇文章《clickhouse聚合之内存不足怎么办?那就提升聚合性能》,我们重点说下如何给聚合提高性能。
本文原创作者:奇想派、一名努力分享的程序员。
文章首发平台:微信公众号【编程达人】

原创不易!各位小伙伴觉得文章不错的话,不妨关注公众号,进行点赞(在看)、转发三连走起!谢谢大家!




的 Java 正则表达式)